

TL;DR
Discover how to effectively model events in your data warehouse with three approaches: single table, wide table, and narrow table, and choose the best model. Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
Benefits of Modeling Events in a Data Warehouse
Teaser
Collecting, storing, and modeling events in a data lake or warehouse has many benefits.
- In 2026, most data lake and warehouse solutions have usage-based pricing models. This means the analytics computation drives up the cost, not the amount of data.
- Your data team is in total control. Fixing quality issues, consolidating user identification is
- A single source of truth, the same data that describes the business, can be reused by all stakeholders.
However the biggest benefit of all is, that event based data models are framework in your data warehouse that can support all business analytics use-cases.
In this post, I will cover 3 data models of how you can model events in the data warehouse and what factors you should consider before deciding on the model that will fit your use-case.All three of these models we have seen while integrating Mitzu with customer data warehouses.
Key Factors to Consider When Choosing an Event Model
- Cost - how much will it cost you to manage and maintain the model? This factor is about the human effort that needs to be put in place.
- Ease of usage - will the data analytics and other stakeholders be able to understand your chosen model? How hard will it be to onboard new people to it? How hard it will be to use this model? Overall mental capacity to understand the model.
- Speed - will your model be responsive and fast to query? How long does an SQL query run before the result is ready?
These three factors are present in each of the event models, and as you will soon see, there is no silver bullet solution. It depends on the business which you should choose.
Three Common Event Models for Data Warehouses
While working with customers at Mitzu we identified 3 major event models that most companies use. I am 100% sure there are more models. But these three comes natural.
1. Single Table Per Event: Simple but Limited for Complex Applications
A single table per event is a model that most likely comes first to your mind as a data engineer. There will be precisely one table in the data warehouse for every event type the client application produces.
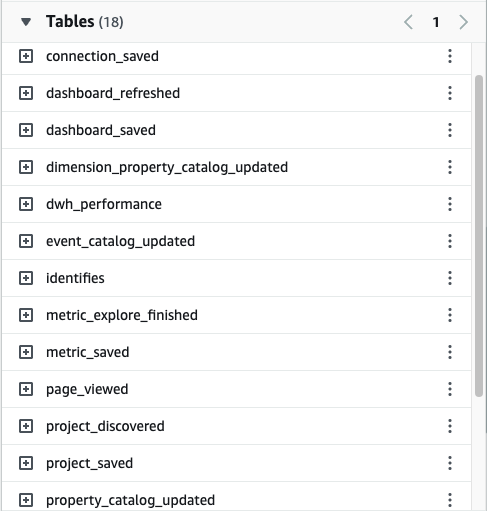
The greatness of this model lies in its simplicity. It is easy to explain and, for the most part, to query. Every table has its own set of columns corresponding to the events' properties. It is also fast to query as each table can be partitioned or indexed by the event's timestamps.
The name of the table describes the type of event precisely.
The problem comes when the client application produces hundreds or thousands of different event types. Just imagine a complex mobile application or a game. Maintaining many tables in the modeling infrastructure like DBT gets exponentially more challenging.
Just imagine renaming an event property (column) or fixing column values in each of the 1000 tables.
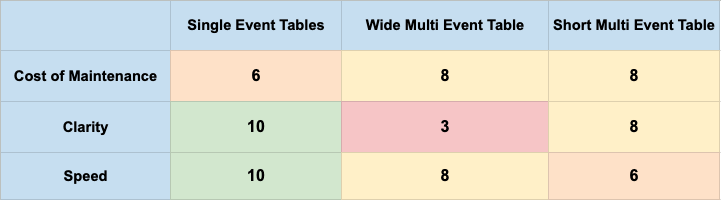
Scores (the higher, the better)
- Cost of maintenance: 6/10 (average)- 2/10 - for complex applications for more than 50 event types- 10/10 - for simple applications with less than 50 event types.
- Clarity 10/10
- Speed 10/10
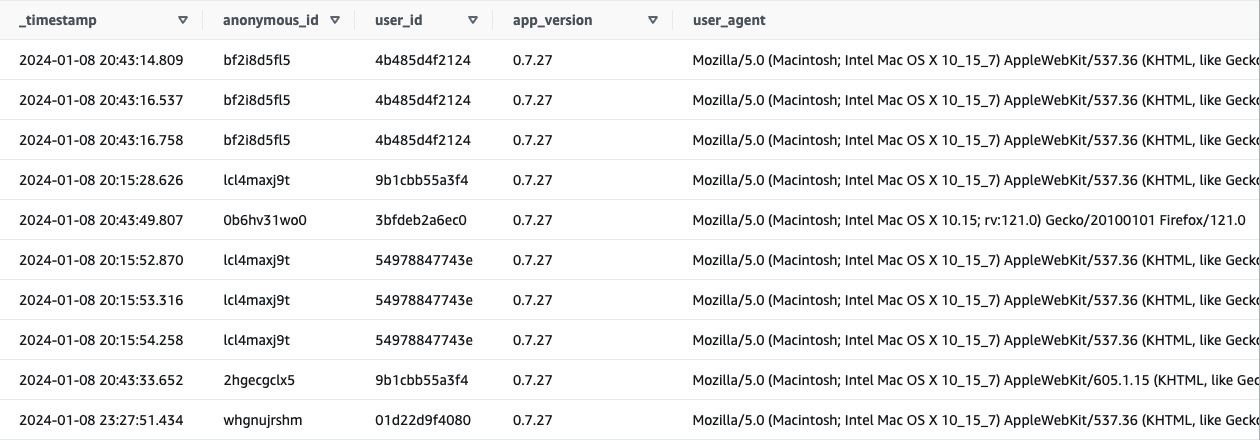
2. Wide One Big Table: Easier Maintenance but Challenging for Query Performance
This event model is the natural answer to the disadvantages of the single-wide event table model. If the data team knows that the client application will produce 1000 different event types, they can decide to store them in a single giant table.
The upside of this event model is that the data team can maintain it relatively easily compared to the 1000 event tables.However, this solution has multiple issues, rendering it impractical.
The Problems:
- Each event has event properties, resulting in an ever-growing number of columns in the table. Imagine 1000 events, where each has at least one event property that is unique to that event.This will result in at least 1000 different columns in the table.
- Partitioning and indexing this table is more complicated as well. The natural date partitioning will yield poor query performance. Why? Because most queries will filter on a set of event types only. However, those queries will scan all event types. Partitioning on the event type column will result in a more complex ingestion process. Especially in the case of a data lake, this will result in many small files.
- Understanding the 1000 columns in this table is a challenge, especially because most event types will have most of these columns filled with Nulls. Forget your lazy select * from queries, which will cost a fortune to execute.
Score (the higher, the better)
- Cost of maintenance: 8/10
- Clarity 3/10
- Speed 8/10
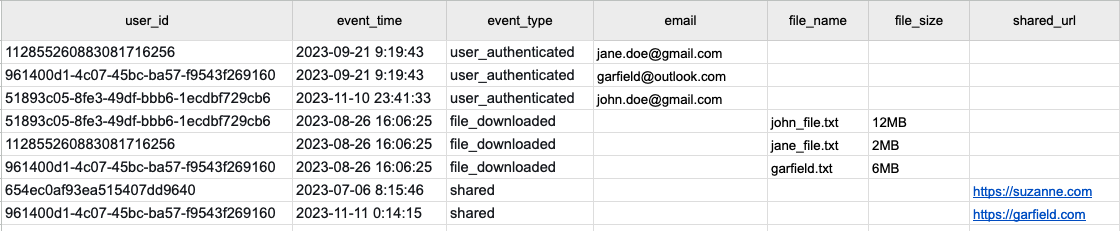
3. Narrow One Big Table: Flexible and Scalable for Complex Use Cases
The biggest downside of the wide one big table is that most of the thousand columns are filled with NULLs for most event types. SQL language dialects don't give an option to ignore null-filled columns. This makes it impractical for data analysts to understand and use this product event model. Determining which columns contain values for which event type is a constant struggle.
The narrow one big table model is a variation of the wide one big table model that solves the clarity problem.
In this model, we store every event type in the same table. However, we keep the individual event properties in a single column with a dynamic type such as JSON (in some cases MAP).
Modeling event properties with a JSON column is excellent because every event can have its unique schema inside the same table.
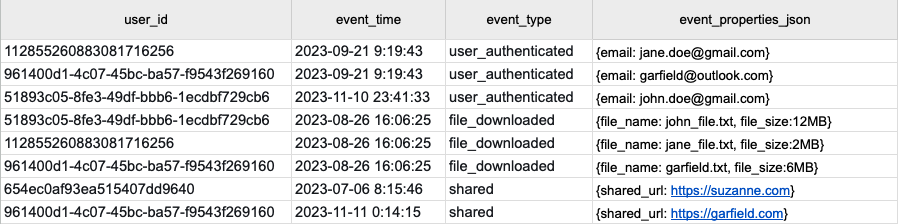
The downside of this solution is that the data analysts will need to use JSON operations in every SQL query they write. This requires some education, and it decreases the performance of the table, as filtering on JSON columns will always require extra CPU time.
Score (the higher, the better):
- Cost of maintenance: 8/10
- Clarity 8/10
- Speed 6/10
How to Choose the Right Event Model for Your Business Needs?
Most companies will choose one of the three models that I described above. Here is a quick guide on which to choose for your scenario.
- Single table for every event - It is best to use when the client-side application produces up to 50 event types.
- Wide one big table - It is rarely a good choice. Choose this model only if your data warehouse doesn't support dynamic types such as JSON or MAP.
- Narrow one big table - It is the best choice for products that produce many event types. It is only usable in data warehouses and lakes where dynamic types are supported.
Final Comparison of Event Models: Costs, Clarity, and Speed
FAQ
What engineering problem is this article addressing?
It focuses on patterns for scaling ingestion, modeling, or governance so downstream analytics—BI or AI agents—does not fight brittle pipelines or ambiguous tables.
When is this approach the right default?
Use it when teams need repeatable pipelines, clear ownership of transformations, and analytics consumers who should trust warehouse tables without ad hoc extracts.
How do permissions and compliance stay coherent?
Centralize grants and row-level policies on the warehouse, document contracts for facts and dimensions, and avoid parallel copies of sensitive data in SaaS-only analytics stores.


