

TL;DR
Understand how to build an efficient data funnel with SQL over event datasets. Learn why 'ugly' funnel queries can yield optimal results in data warehouses.
Treat this playbook as an implementation path for agentic analytics: design the AI data analyst workflow around trusted SQL and a trusted semantic layer so answers stay explainable, reusable, and safe for business decisions.
We document evaluation criteria as of 2026: data architecture (warehouse-native versus copied event stores), governance, product analytics depth (funnels, retention, journeys), and self-serve access for non-technical teams. See Databricks lakehouse guidance and Apache Iceberg documentation where table formats matter.
Understanding your user's journey is more than just advantageous. It's critical for success. Funnel metrics emerge as the linchpin in product analytics, offering a clear view into the user's pathway from initial engagement to conversion. They are the roadmap guiding businesses to identify bottlenecks, optimise user experiences, and make data-driven decisions.
During the development of Mitzu we optimised our funnel query-building engine to support all our customers. In this process, we conducted interviews with various data analysts to understand their approaches to crafting a funnel query using SQL language.
We have identified three ways data teams in companies write these queries:
- The good
- The bad
- The ugly
Each of these has specific characteristics that we will discuss in this post.
The Setup
Before we jump into SQL query writing, let us first explore the typical data upon which the data team executes these queries.
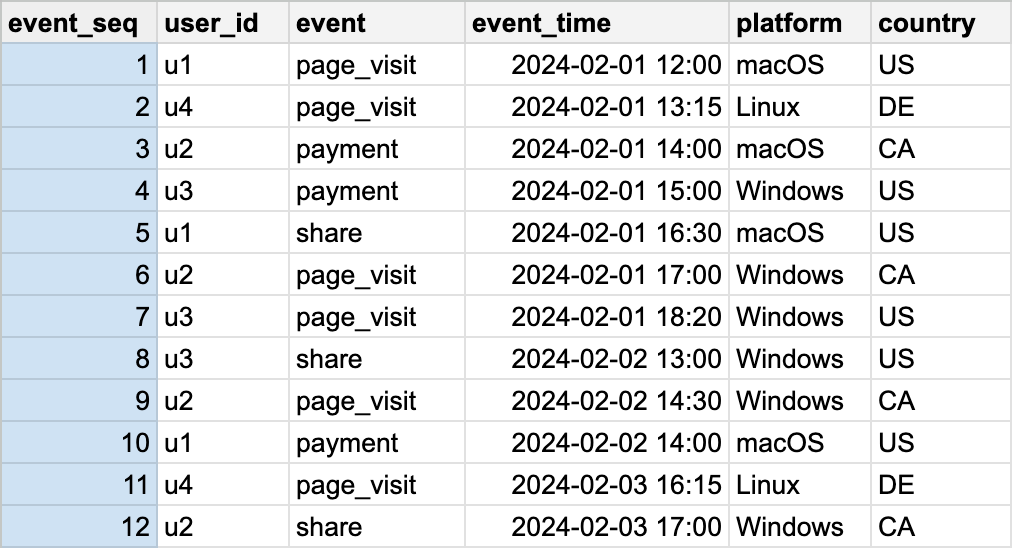
This dataset is called a behavioural event dataset or just an event dataset. In this post, we are going to examine a simple funnel question:
What is the daily ratio of users who visited our website and paid for something within a day?
The Bad (naive approach)
Let's start with the worst of all. Why is it the bad one? Simply because it doesn't yield correct results. Junior data analysts typically write this query.
The main issue is that it doesn't connect the users who did "page visit" and then "payment" events. It simply divides two numbers that can yield weird results. Often, the conversion rate is more than 100%, which is already something of concern.
| Characteristic | Comment |
|---|---|
| Code complexity | very simple |
| Time complexity | O(n) |
| Space complexity | O(n) |
| Results | inaccurate |
| Usage recommendation | never |
The Good (left joins)
Next in line comes "the good" query (as we call it). This query connects the users across their events and takes care of the correct funnel window filter. This is "the good" solution, as it will yield good results. However, it is not a perfect solution, as you will see.
| Characteristic | Comment |
|---|---|
| Code complexity | medium complexity |
| Time complexity | O(n^2) |
| Space complexity | O(n^2) |
| Results | precise |
| Usage recommendation | small to medium size datasets |
The Ugly (window functions)
The previous approach gave good results but became slow on more extensive datasets. The third solution, "the ugly," is here to save us. See, the O(n^2) space complexity comes from the fact that we are trying to match every "page visit" event with every "payment" event. At least this will be the result of the JOIN.
However, a single payment event after a page visit is enough to yield a successful conversion.
The solution is not to use joins but UNION ALL and window functions. Modern SQL-based data warehouses and data lakes support window functions. They are easy to start with but tricky to master. In the following query, the idea is to sort the union-ed events by their timestamp.
This way, consecutive events will come after each other in the dataset. After this, the clever use of the LEAD window function finds the next payment event's timestamp right after any page visit. The key is to look up only the following first payment event, not each, as in the case of the JOIN.
| Characteristic | Comment |
|---|---|
| Code Complexity | Can Get Very Complex |
| Time Complexity | O(n^2) |
| Space Complexity | O(n) |
| Results | Precise |
| Usage Recommendation | Large Datasets, Millions Or Billions Of Events |
What Are the Key Takeaways?
As you can see, there are multiple ways to write funnel SQL queries over an event dataset. Some are good, some are bad, some are plain ugly. However, sometimes "ugly" leads to the most optimal results.
We apply the "ugly" funnel queries in Mitzu to all data lakes and data warehouses that support the LEAD window function with the IGNORE NULLS argument, as this query is the fastest and most likely won't cause issues in the cluster. This approach opens the door for warehouse native product analytics. It nullifies the argument that data warehouses can't query event datasets fast enough. We have seen companies having billions of events monthly stored in their data warehouse while having funnel queries executed within 3-4 seconds.
In an upcoming blog post I will cover how to apply window functions to retention queries, so stay tuned!
with page_visits as (
select
date(event_time) as day,
count(distinct user_id) as user_count
from events
where event = 'page_visit'
),
payments as (
select
date(event_time) as day,
count(distinct user_id) as user_count
from events
where event = 'payment'
)
select
t1.day,
t2.user_count * 100 / t1.user_count as conversion_rate
from page_visits t1
join payments t2 using(day)with page_visits as (
select
event_time,
user_id
from events
where event = 'page_visit'
),
payments as (
select
event_time,
user_id
from events
where event = 'payment'
)
select
t1.day,
count(distinct t1.user_id) * 100 / count(distinct t2.user_id) as conversion_rate
from page_visits t1
left join payments t2 on
t1.user_id = t2.user_id
and t2.event_time > t1.event_time
and t2.event_time <= t1.event_time + interval '1' daywith all_events as (
select
user_id,
event,
event_time
from events
),
conversion_times as (
select
user_id,
event,
event_time as event_time_1,
case event = 'page_visit'
then lead(case event='payment' then event_time end) ignore nulls
over (partition by user_id order by event_time asc)
else null
end as event_time_2
from all_events
),
filtered_conversions as (
select
user_id,
event_time_1,
case event_time_2 <= event_time_1 + interval '1' day
then user_id
else null
end as converting_user_id
from conversion_times
where event = 'page_visit'
)
select
date(event_time_1) as day,
count(distinct user_id) * 100 / count(distinct converting_user_id) as conversion_rate
from filtered_conversionsFAQ
What engineering problem is this article addressing?
It focuses on patterns for scaling ingestion, modeling, or governance so downstream analytics—BI or AI agents—does not fight brittle pipelines or ambiguous tables.
When is this approach the right default?
Use it when teams need repeatable pipelines, clear ownership of transformations, and analytics consumers who should trust warehouse tables without ad hoc extracts.
How do permissions and compliance stay coherent?
Centralize grants and row-level policies on the warehouse, document contracts for facts and dimensions, and avoid parallel copies of sensitive data in SaaS-only analytics stores.


