Data Mesh vs Data Fabric: Scalable Enterprise Data

As enterprise data grows in scale and complexity, understanding modern data architectures is critical. Data Mesh decentralizes data ownership, treating data as a product managed by domain teams, while Data Fabric uses a unified, metadata-driven layer for integration, governance, and access.
This article explores their key technical differences and approaches to scaling data in the enterprise.
Decentralized Domains vs Centralized Integration
At its core, Data Mesh decentralizes data ownership by assigning responsibility to domain-aligned teams. Each domain acts as a data product owner, accountable for its pipelines, quality, governance, and accessibility. This contrasts with centralized data lakes or warehouses managed by dedicated teams.
Example: In a large e-commerce platform, the Customer Domain manages customer profiles in Snowflake, building data products via dbt and exposing them through APIs. The Order Domain independently handles transactional data and Kafka streams, sharing summarized datasets. This setup allows fast innovation under clear ownership without bottlenecks.
Data Fabric, by contrast, centralizes data management through a metadata-driven architecture, integrating diverse sources - structured, unstructured, on-prem, and cloud - into a seamless, federated layer.
Example: A global bank using Denodo abstracts on-prem databases, cloud data lakes, and streaming systems. Analysts query the fabric, which intelligently routes, optimizes, and secures data access, delivering rapid insights without data replication.
Data Lifecycle and Processing Flows
Data Mesh data flow
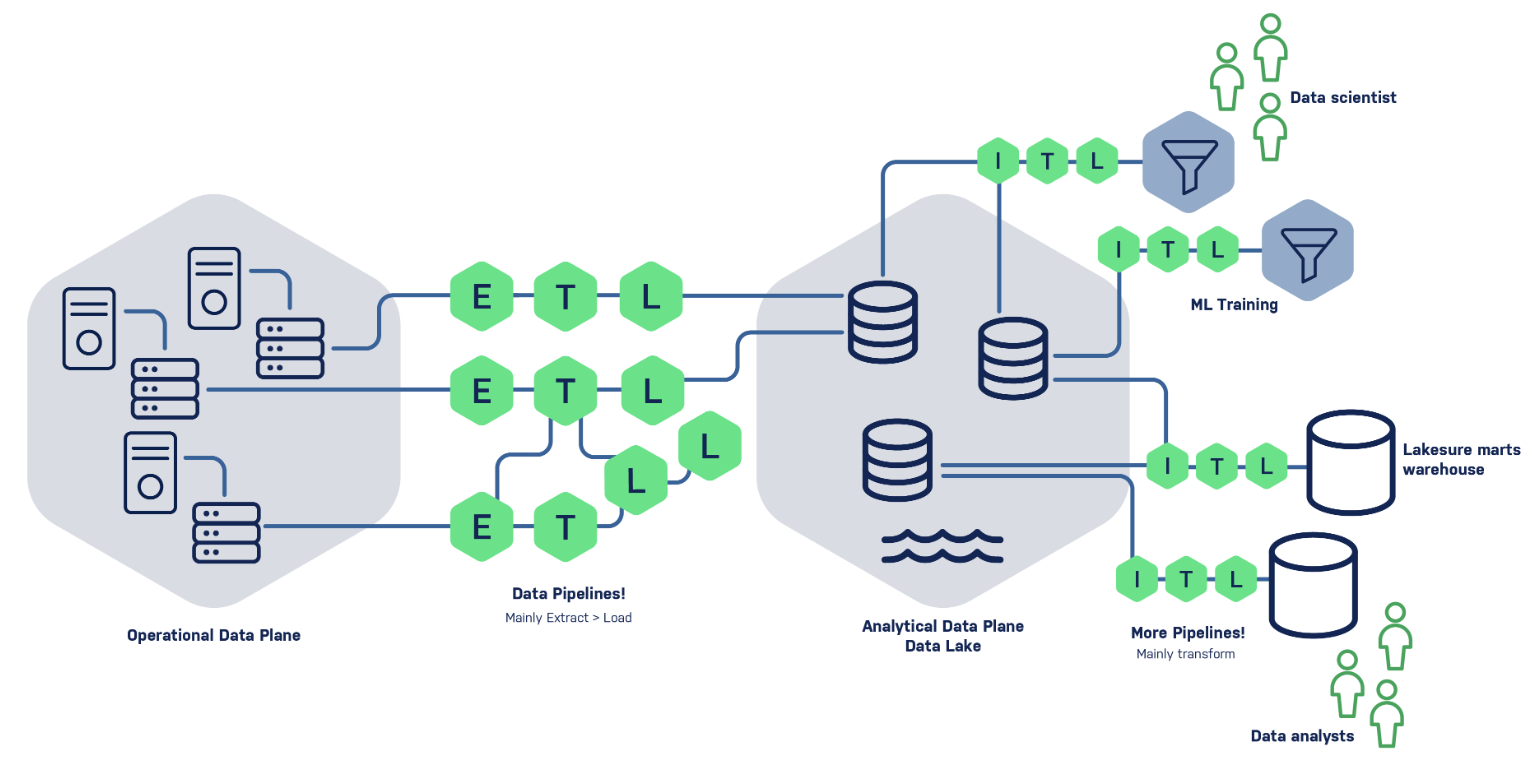
- Domains ingest raw data independently using tools like Kafka Connect or CDC pipelines.
- They manage ETL/ELT pipelines to create served data products.
- Consumers access data via domain-controlled APIs or query layers.
- Federated governance enforces local SLAs, quality, and compliance.
- Multiple parallel pipelines feed domain-owned stores with independent monitoring and APIs
Data Fabric data flow
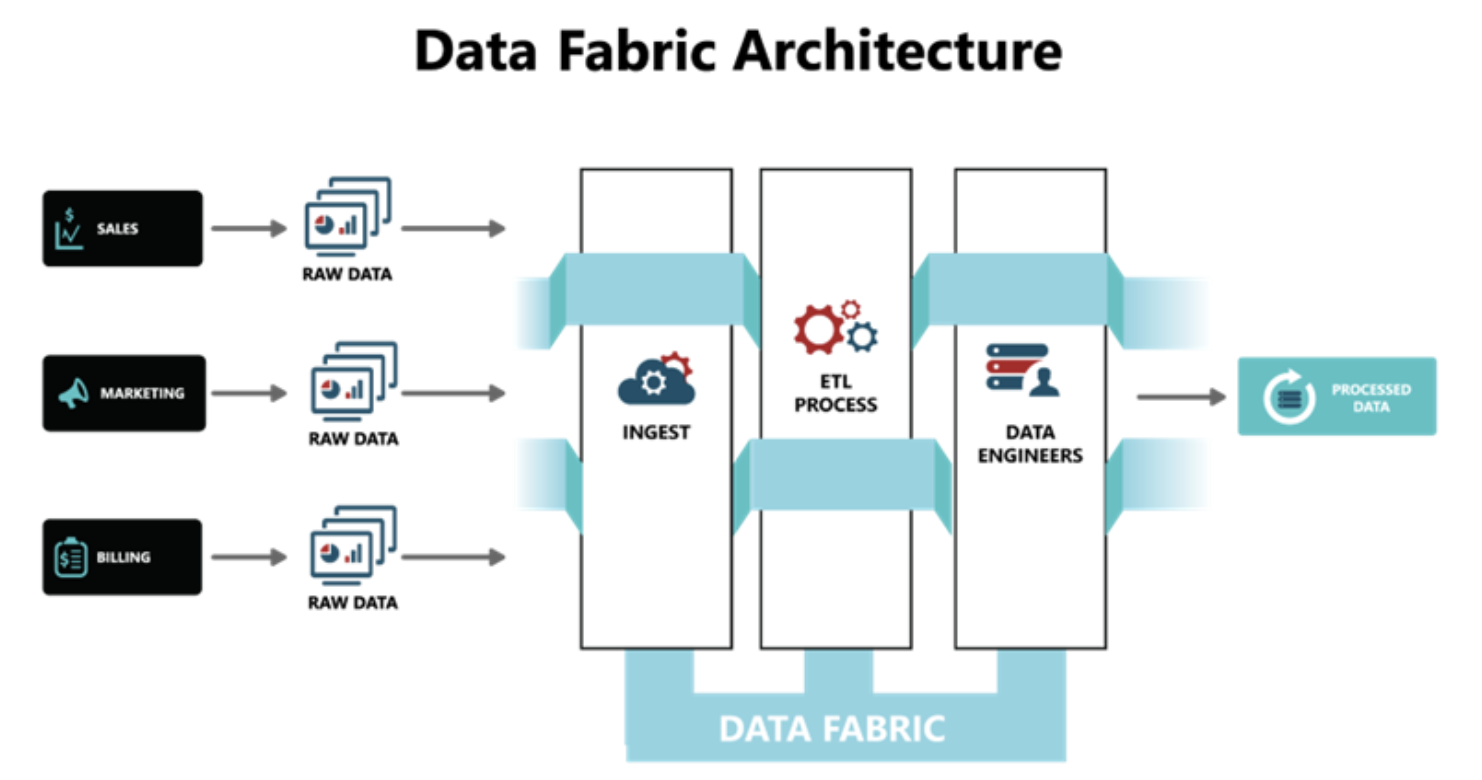
- Data is automatically ingested from multiple sources.
- Metadata-driven orchestration manages workflows and replication.
- Data virtualization enables real-time queries without moving data.
- Centralized governance enforces security, quality, and compliance.
Technical Differences in Analytics
In Data Mesh, analytics succeed when domains deliver data products that meet global SLAs, giving analysts trusted datasets while enabling innovation.
Data Fabric provides a single view to find, query, and govern data, using automation to speed up data preparation and enforce compliance.
Mitzu’s warehouse-native analytics platform supports both approaches, offering fast, reliable analytics directly in cloud data warehouses. It lets domains run self-service SQL on their data products while maintaining governance through warehouse security and auditing.
By bridging decentralized and centralized models, Mitzu helps teams deliver insights quickly and confidently.
When to Use Data Mesh or Data Fabric
Choose Data Mesh if:
- Your organization is large and domain-diverse with mature engineering teams.
- You want to foster agility and innovation through decentralized ownership.
- Complex domain-specific data transformations require localized autonomy.
- Example use case: A SaaS company with isolated product lines needing domain-driven analytics.
Choose Data Fabric if:
- You need rapid, centralized deployment for consistent data governance.
- Your data estate spans multiple, heterogeneous technologies.
- Metadata-driven automation and real-time data virtualization are priorities.
- Example use case: A multinational banking institution integrating legacy and modern systems.
Unbeatable solution for all of your analytics needs
Get started with Mitzu for free and power your teams with data!



