
TL;DR
Real-time streaming and event-driven architectures enable instant data processing and analytics, keeping insights fresh and systems responsive at any scale. Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
Use this comparison to evaluate tools through an agentic analytics lens: which platform enables an AI data analyst workflow with trusted SQL and a trusted semantic layer, not just faster dashboarding.
We document evaluation criteria as of 2026: data architecture (warehouse-native versus copied event stores), governance, product analytics depth (funnels, retention, journeys), and self-serve access for non-technical teams. See Google Cloud's data warehouse overview and Snowflake documentation.
Real-Time Streaming & Events: Foundations of Modern Systems
When you're building or upgrading a data pipeline, using real-time streaming and event-driven architecture lets you handle things like user actions, campaign triggers, or product updates right as they happen. That means your dashboards stay fresh, and you can react quickly instead of waiting on batch jobs.
The key isn’t just choosing between batch or real-time processing. It’s about designing a system that balances data freshness with reliability and simplicity. Most setups combine both approaches, treating latency as a configurable setting to fit your needs.
What is Real-Time Data Streaming?
Real-time streaming moves data as soon as it’s created. No waiting for hourly or daily batch jobs, you can process and react to events right when they happen. It’s the difference between scheduled updates and working with live data.
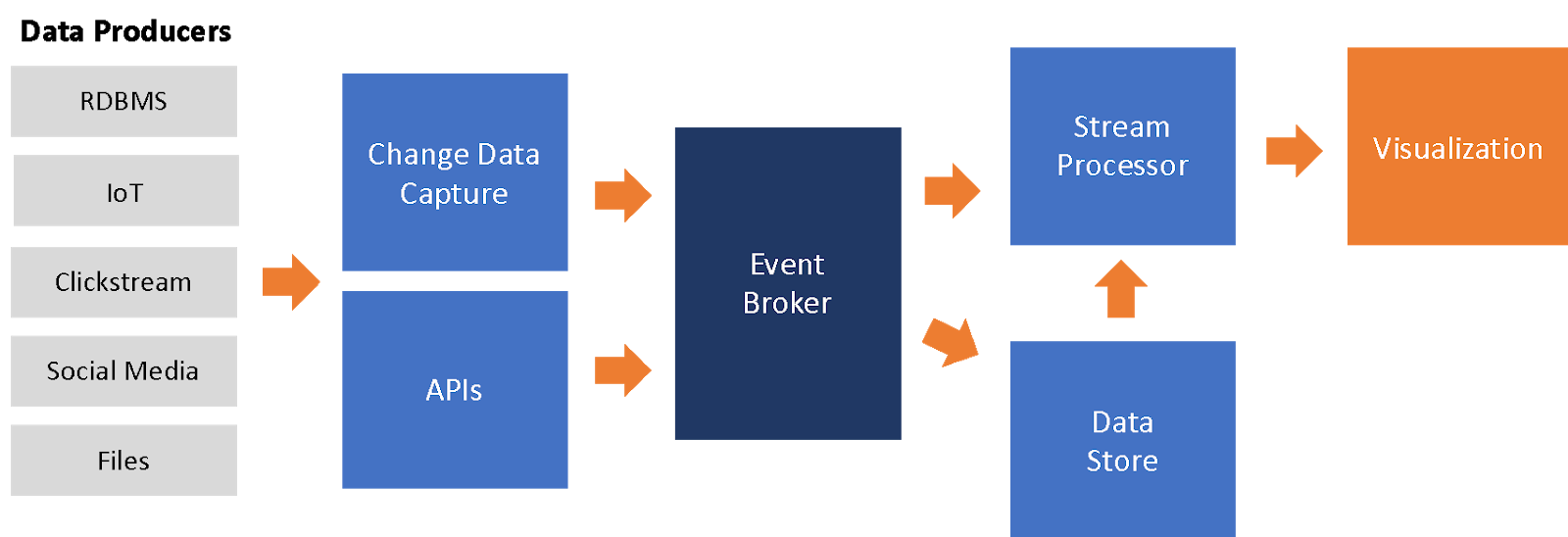
How does it work?
- Producers: These are your data sources, a mobile app, a sensor, or a website.
- Streaming Platform: Tools like Apache Kafka, Redpanda, or AWS Kinesis act as the “pipes” that move data from producers to consumers.
- Consumers: These are the apps or services that use the data, whether it’s for analytics, alerts, or updating a dashboard.
Where is it used?
- E-commerce: Personalized offers, dynamic pricing, real-time inventory updates.
- SaaS: Live user activity tracking, real-time analytics, CI/CD pipeline monitoring.
- Travel: Instant booking confirmations, itinerary updates, and real-time availability.
- Gaming: In-game event processing, live leaderboards, multiplayer sync.
- Media: Personalized recommendations, interactive live events, real-time engagement analytics.
In reality, many of these use cases blend batch and streaming. A system might stream data in near-real-time for critical updates while aggregating hourly metrics in batch jobs for cost-effective reporting. What matters most is delivering the right data at the right time.
What is Event-Driven Architecture (EDA)?
Event-driven architecture (EDA) is a way to build systems where different parts react to events as they happen, without waiting on each other. An event can be anything, such as a button click, a completed payment, or a shipped package.
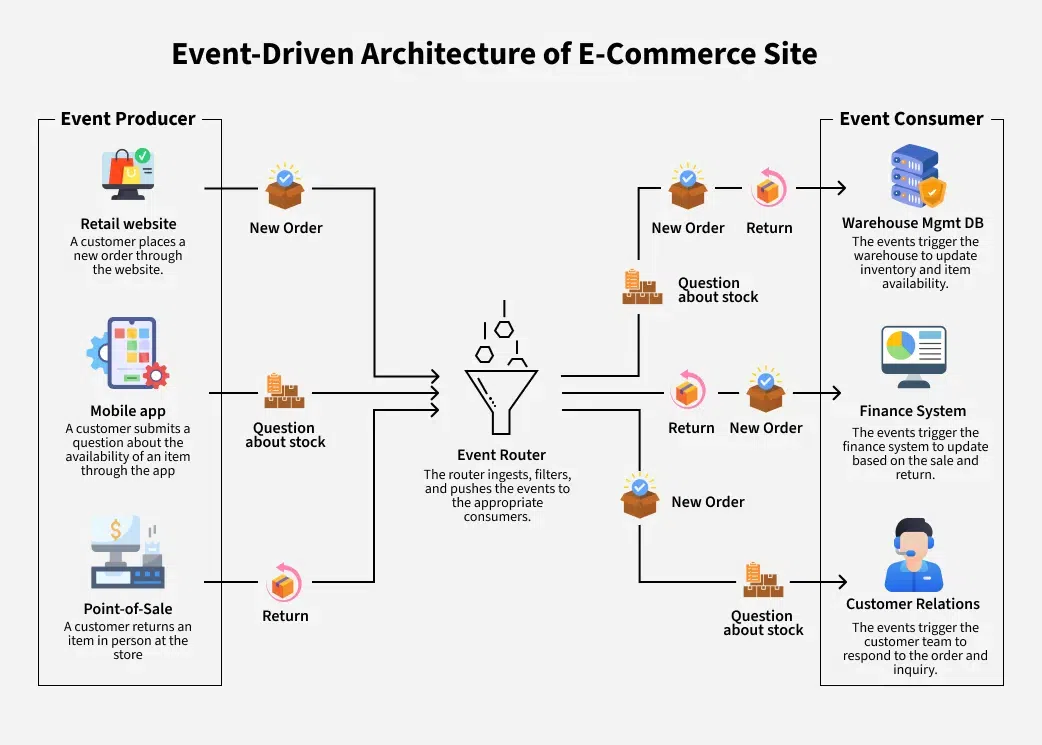
How does it work?
- Events are generated and sent to an event broker, like Kafka or AWS Kinesis.
- Independent services subscribe to and respond to these events like sending emails, updating databases, or triggering other actions.
- These services are decoupled, meaning they don’t need to be aware of each other.
Why is this beneficial?
- Scalability: Multiple services can respond to events concurrently.
- Flexibility: Adding new functionality is easier because services are loosely coupled.
- Resilience: If one consumer fails, others continue operating.
EDA complements streaming well by treating data not just as a payload to move, but as a trigger to act. It's part of why the boundary between streaming and event-based design is increasingly blurry; many platforms now support both paradigms seamlessly.
Integration: Streaming + EDA in Modern Analytics
Real-time data streaming and event-driven architecture (EDA) are key pieces of modern data systems. Streaming moves data fast and efficiently, while EDA shapes how systems react to each event in real time.
Used together, they make it easier to build scalable, decoupled services that support live analytics, faster operations, and cleaner system design. Each part of the stack plays a clear role and when everything fits together well, you get a fast, reliable pipeline that takes data from raw input to real-time insight.
1. Event Ingestion
At the entry point, use a distributed event streaming platform like Apache Kafka, Amazon Kinesis, or Redpanda. These systems handle high-throughput ingestion with durable, ordered, and partitioned logs.
- Partition by keys like user_id or order_id for scalability.
- Use schema enforcement (e.g., Avro, Protobuf) with tools like Confluent Schema Registry to maintain compatibility and integrity across services.
2. Stream Processing
Once events are ingested, process them in real time using engines like Apache Flink or Spark Structured Streaming.
- Flink supports event-time semantics, stateful operations, and exactly-once delivery—ideal for complex, low-latency pipelines.
- Spark Structured Streaming is suited for micro-batch processing, offering tight integration with batch pipelines and SQL APIs.
Common processing tasks include filtering, joins, enrichment, aggregations, and windowing.
3. Storage
Processed data should be persisted for both long-term retention and analytical access:
- Store raw and enriched data in object storage (e.g., S3, GCS) using Parquet or ORC for efficient batch reads.
- Stream cleaned and modeled data into cloud data warehouses like Snowflake, BigQuery, or Redshift for fast, interactive querying.
Partition data by time and key dimensions to optimize performance.
4. Monitoring & Observability
To operate at scale, real-time pipelines require full visibility:
- Collect system and application metrics from streaming, processing, and storage layers.
- Visualize key performance indicators and configure alerts for critical metrics such as consumer lag, throughput, and processing latency.
- Employ distributed tracing to monitor data flow across the architecture and pinpoint bottlenecks in the system.
5. Analytics & Visualization
At the top of the stack, expose insights to business users through robust modeling and visualization layers:
- Define metrics and transformations directly within the analytical platform to ensure consistency across reports.
- Connect product analytics like Mitzu, which provide native integration with streaming systems and cloud warehouses, enabling real-time analytics with sub-minute visibility for instant dashboarding and reporting.
Final Thoughts
Real-time streaming and event-driven architectures aren't about rejecting batch but about building systems that respond at the right speed, with the right tools, and with minimal friction. Trusted agentic analytics completes this picture by letting teams analyze fresh data directly in the warehouse, ensuring insights are always current and accessible without added complexity. The distinction between batch and real-time is increasingly nuanced: they differ in how events are distributed (push vs. pull, steady vs. bursty), but both serve critical roles in a modern stack.
The best data architectures don’t separate data from applications. They’re flexible, balancing speed and simplicity, and deliver the data you need when and how you need it.
FAQ
What analytics question does this article answer?
It connects business or product outcomes to the metrics, segments, and semantic-layer grounded patterns teams use so stakeholders do not debate methodology in every meeting.
What should leaders prioritize first?
Stabilize definitions for key events and KPIs, ensure funnels and retention can be reproduced from the warehouse, then expand self-serve and automation on top of those truths.
How does AI or agentic analytics fit here?
Agents work best when prompts and answers map to governed models. Read AI analytics for how that differs from chat that ignores warehouse semantics.


